Functional Data Analysis
An Overview
J. Derek Tucker 
Sandia National Laboratories
June 4, 2024
References
- “Functional Data Analysis”, By James Ramsay, B. W. Silverman
- Standard Textbook covers basic methods with a basis-based approach

References
- “Functional and Shape Data Analysis”“, By Anuj Srivastava, Eric P Klassen
- Recent book on advances using more theoretical foundations

Introduction
- Problem of statistical analysis of function data (FDA) is important in a wide variety of applications
- Easily encounter a problem where the observations are real-valued functions on an interval, and the goal is to perform their statistical analysis
- By statistical analysis we mean to compare, align, average, and model a collection of random observations
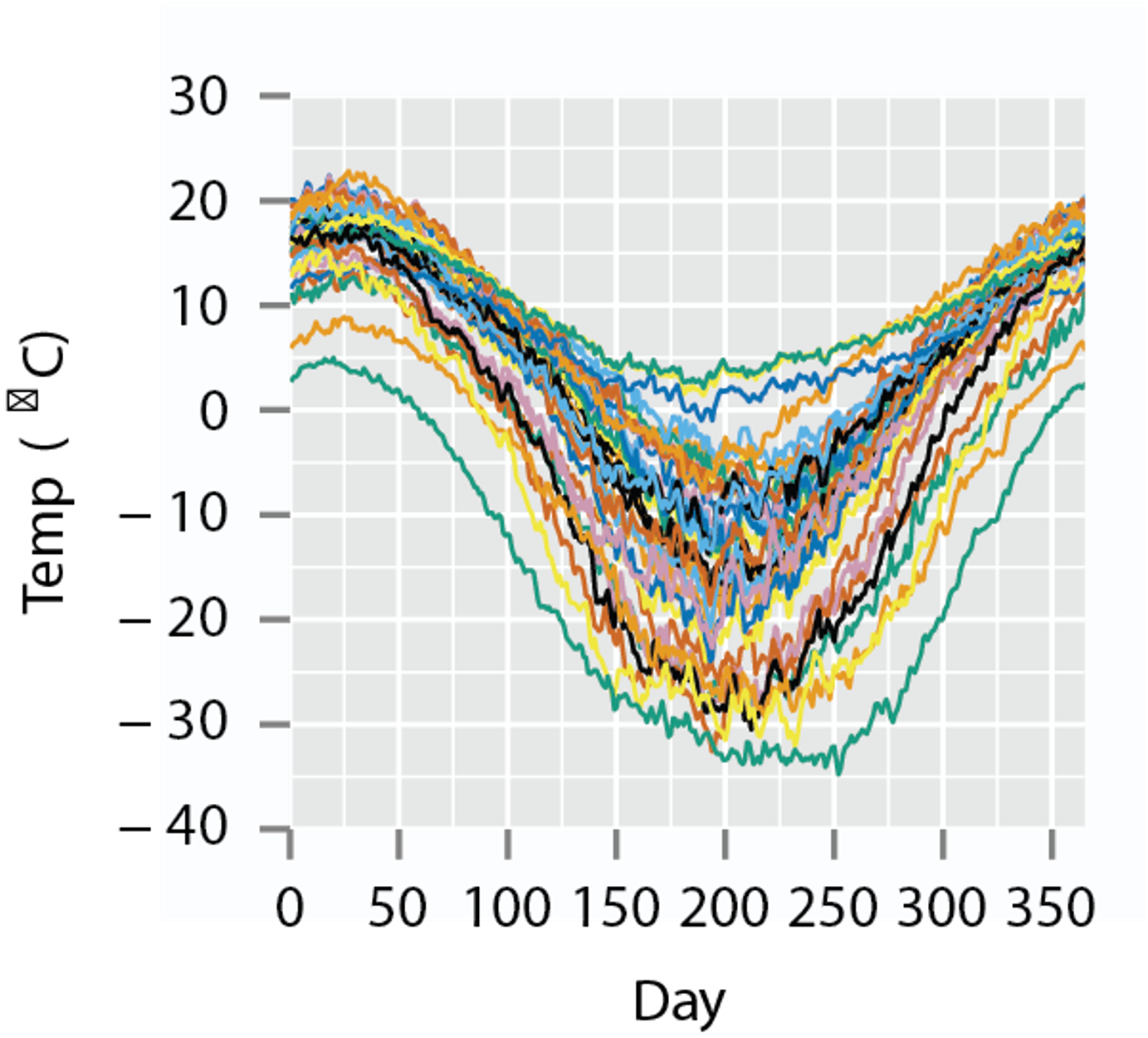
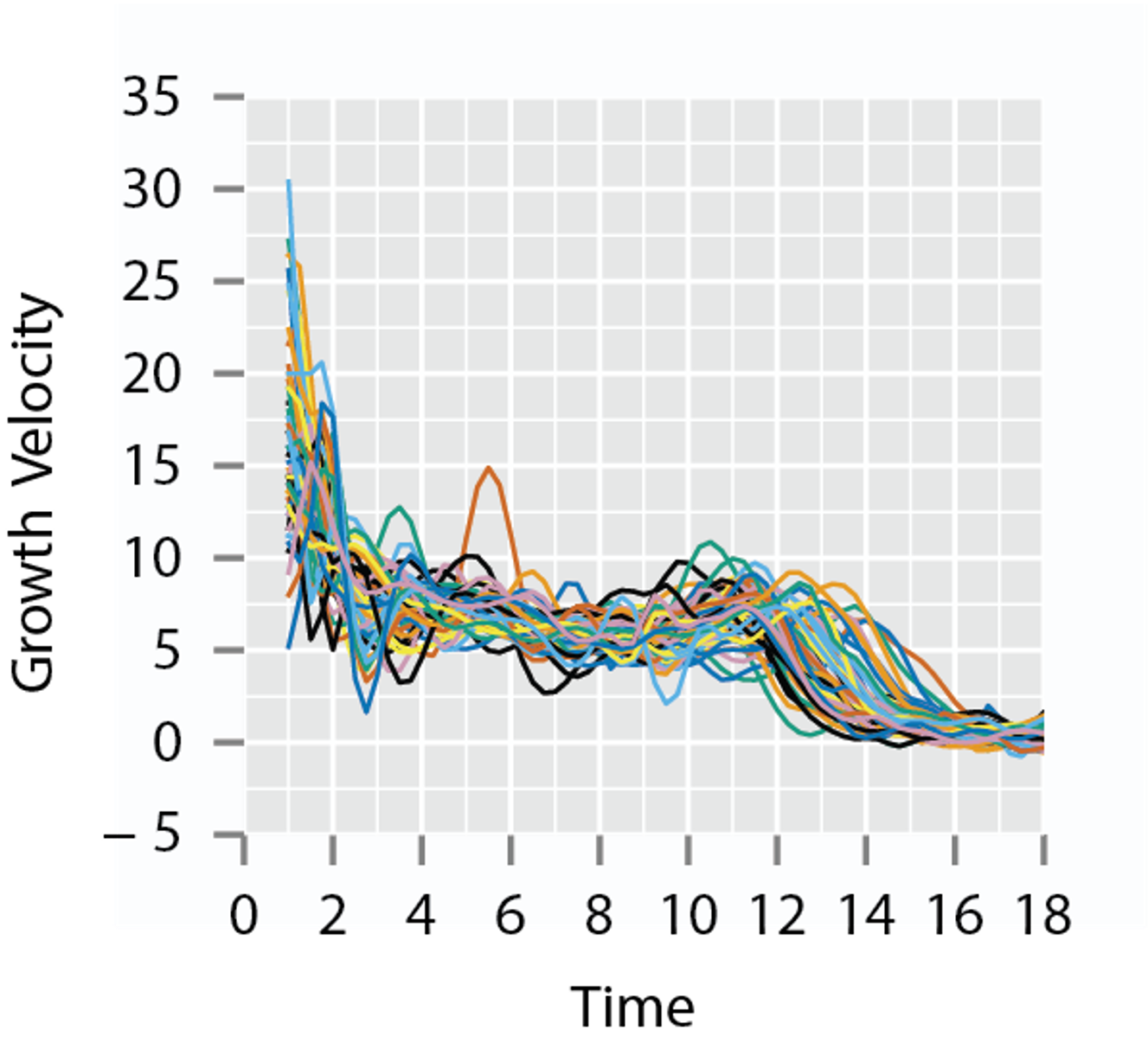
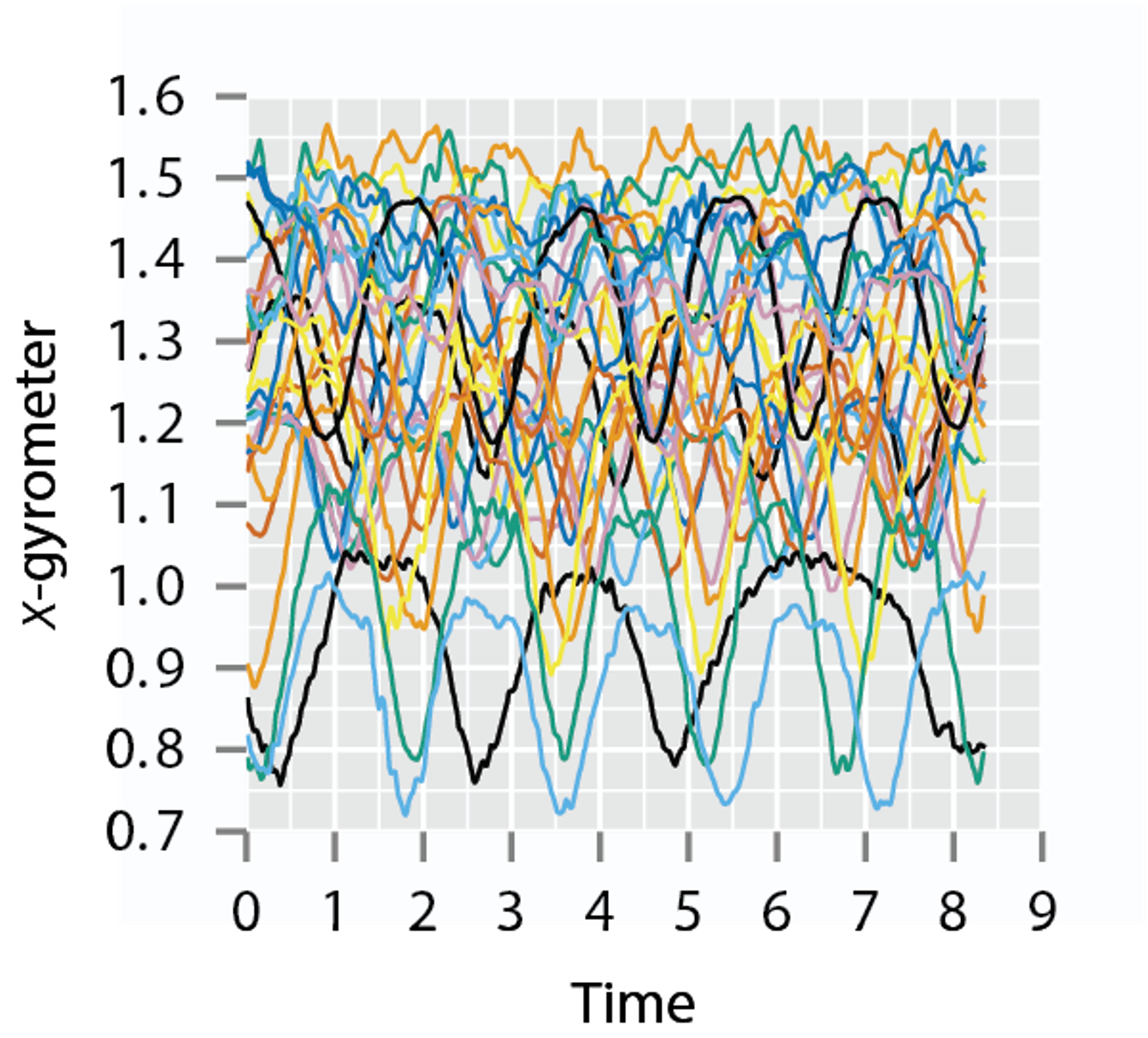
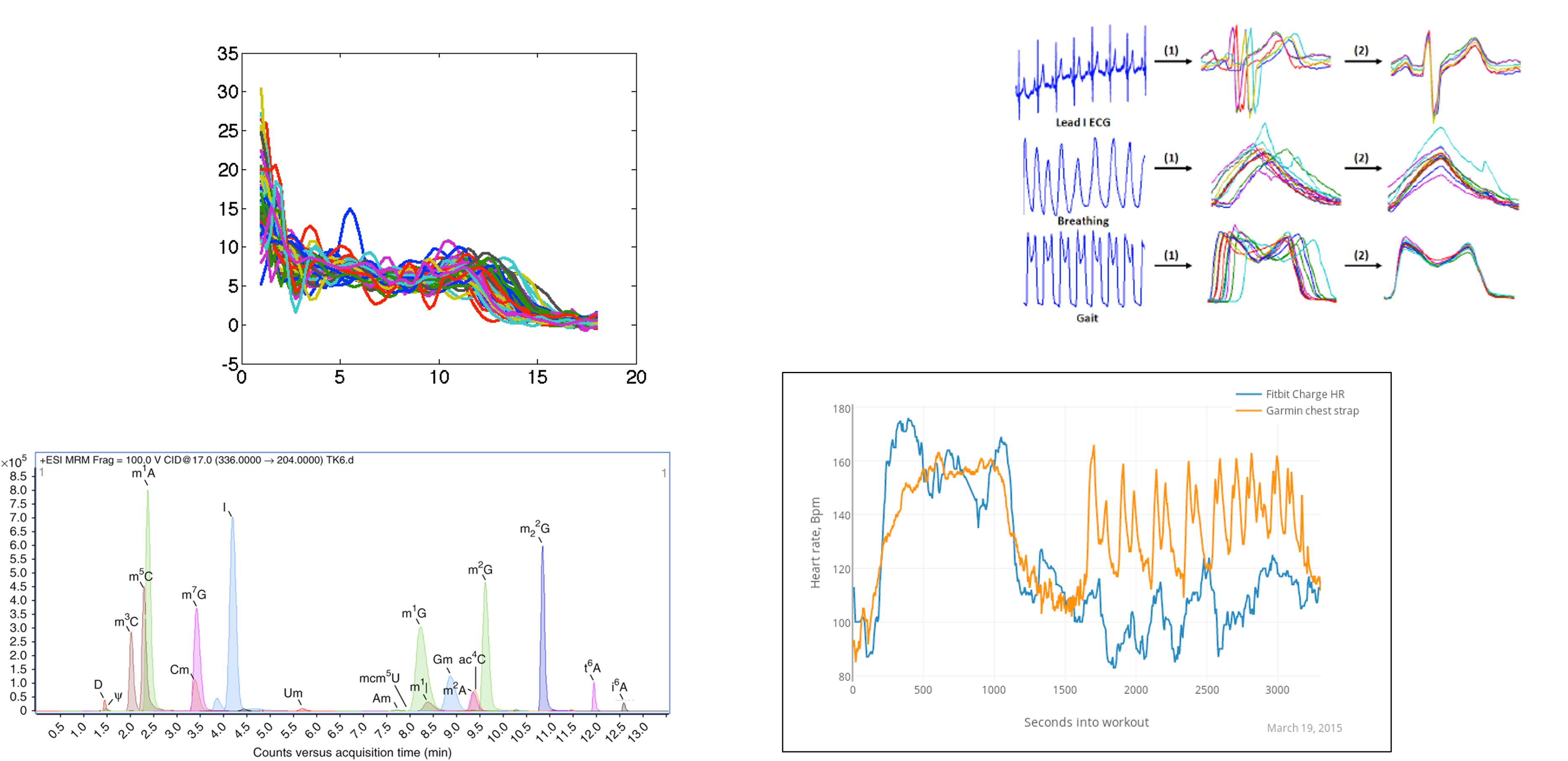
Types of Functional Data
- Real-valued functions, with interval domain: \(f:[a,b]\rightarrow\mathbb{R}\)
Types of Functional Data
- \(\mathbb{R}^n\)-valued functions with interval domain, Or Parameterized Curves: \(f:[a,b]\rightarrow\mathbb{R}^n\) \(f:S^1\rightarrow\mathbb{R}^n\)
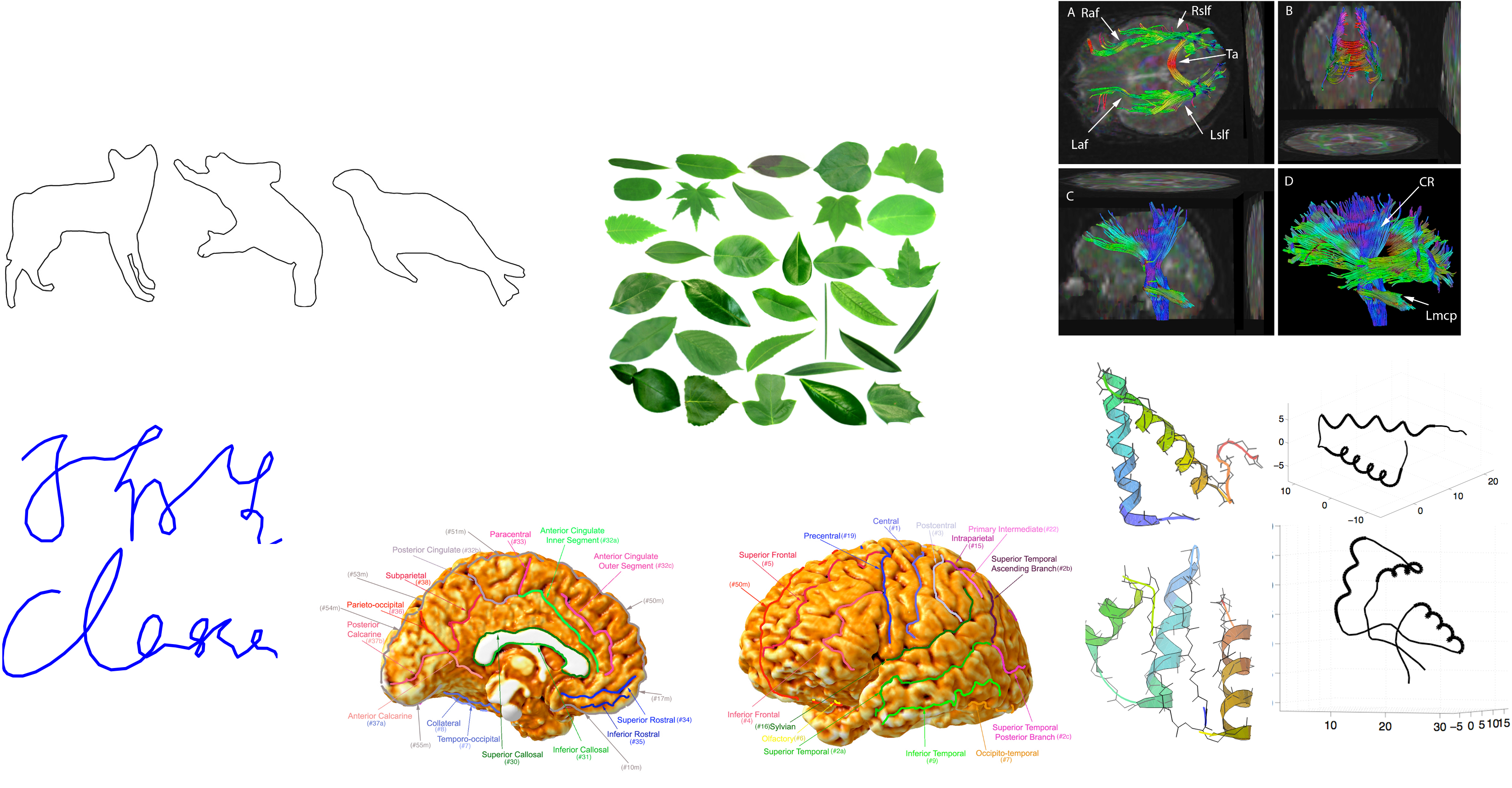
Types of Functional Data
- \(\mathbb{R}^3\)-R3-valued functions on a spherical domain, Or Parameterized Surfaces: \(f:S^2\rightarrow\mathbb{R}^3\)
Types of Functional Data
- \(\mathbb{R}^n\)-valued functions with square or cube domains, Or Images: \(f:[0,1]^2\rightarrow\mathbb{R}^n\)
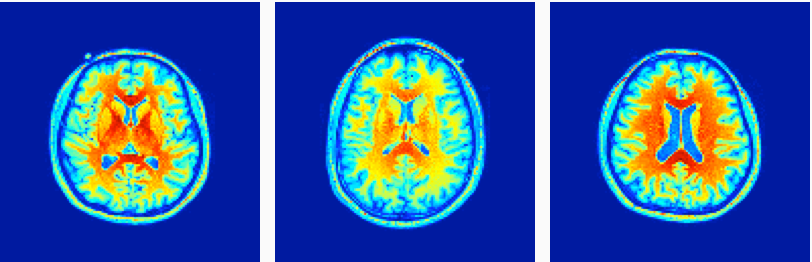
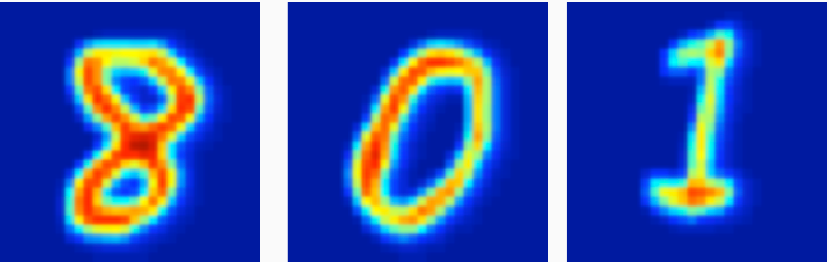
FDA Versus Multivariate Statistics
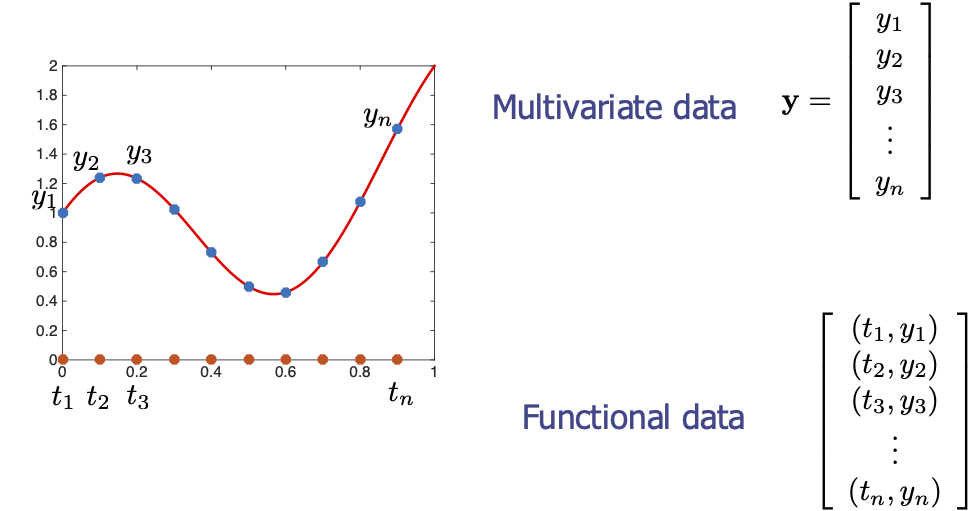
- Not all observations will have the same time indices
- Even if they do, we want the ability to change time indices
FDA Versus Multivariate Statistics
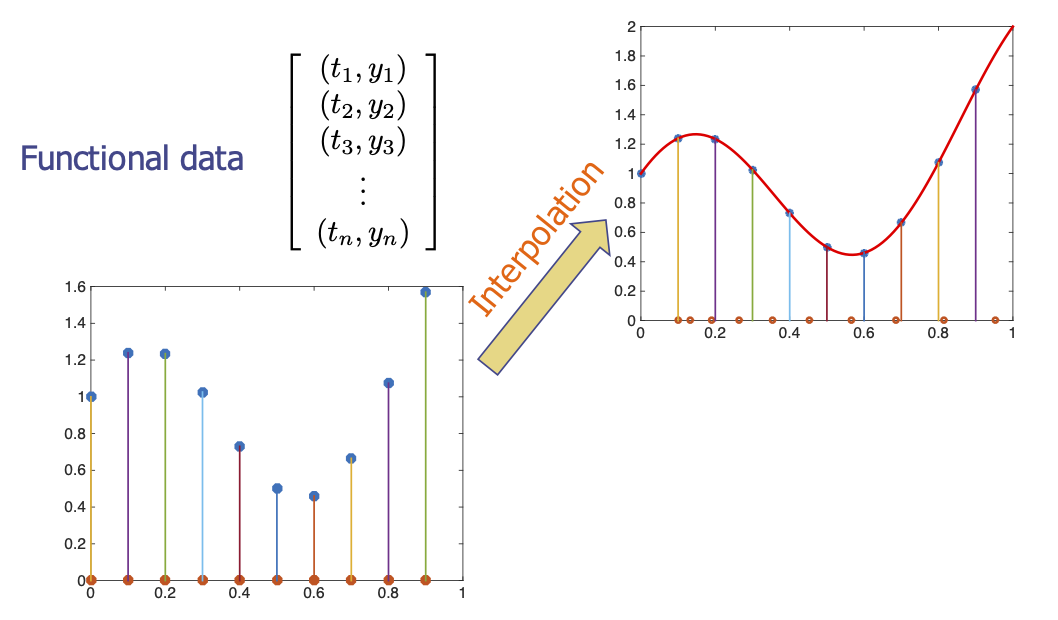
FDA Versus Multivariate Statistics
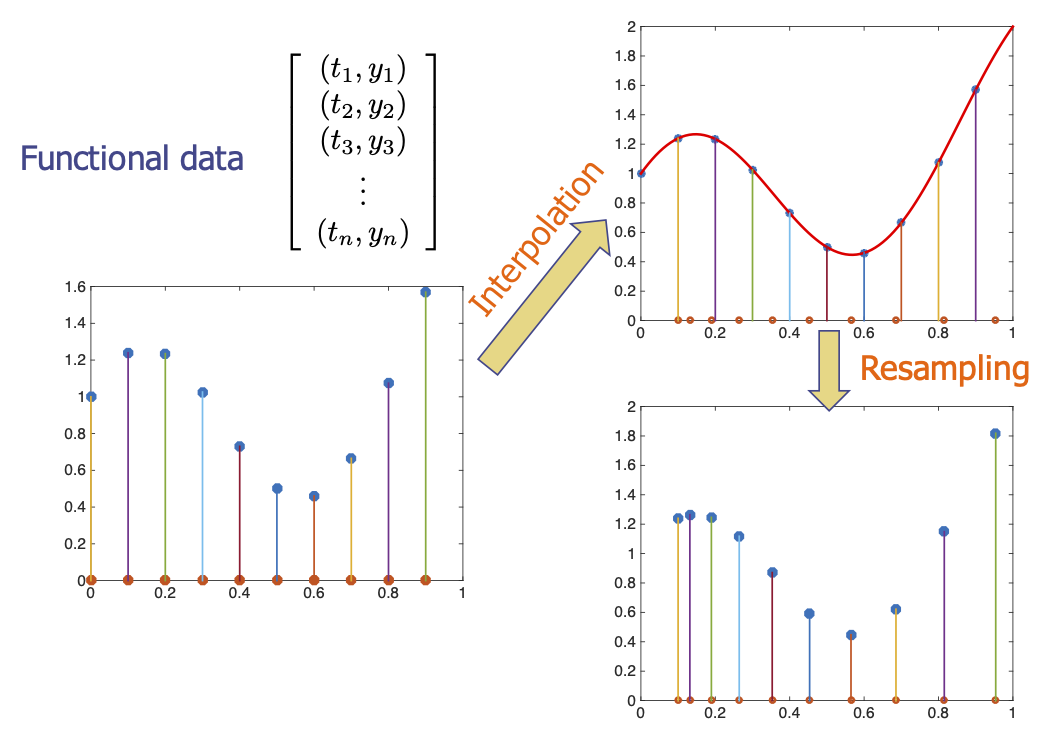
FDA Versus Multivariate Statistics
- In FDA, one develops the on function spaces and not finite vectors, and discretizes the functions only at the final step – computer implementation.

- Ulf Grenander: “Discretize as late as possible” (1924-2016)
- Even after discretization, we retain the ability to interpolate resample as needed!
Representing Functions by Basis Functions
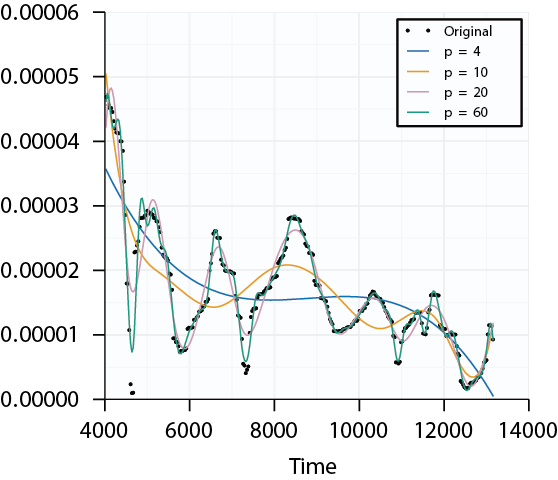
- Setting the dimension of the basis expansion \(p\) we can control the degree to which the functions are smoothed
- Choosing \(p\) large enough we can fit the data well, but might fit any additive noise
Roughness Penalty
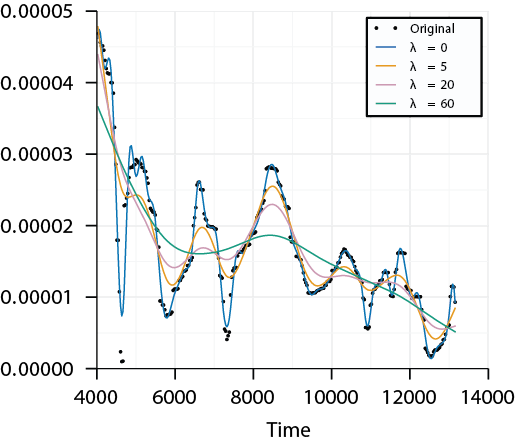
- The parameter \(\lambda\) is the smoothing parameter and controls the amount of smoothing
Phase Amplitude Separation
- All of these methods assume the data has no phase-variability or is aligned
- How does this affect the analysis?
- Can we account for it?
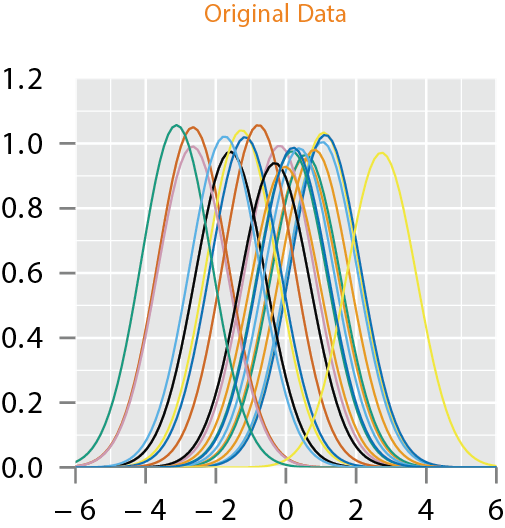
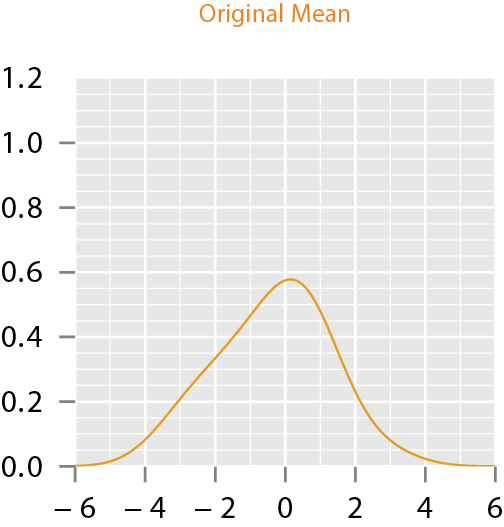
Motivation
- If one performs fPCA on this data and imposes the standard independent normal models on fPCA coefficients, the resulting model will lack this unimodal structure
- A proper technique is to incorporate the phase and amplitude variability, into the model construction which in turn incorporates into the component analysis
Functional Data Alignment
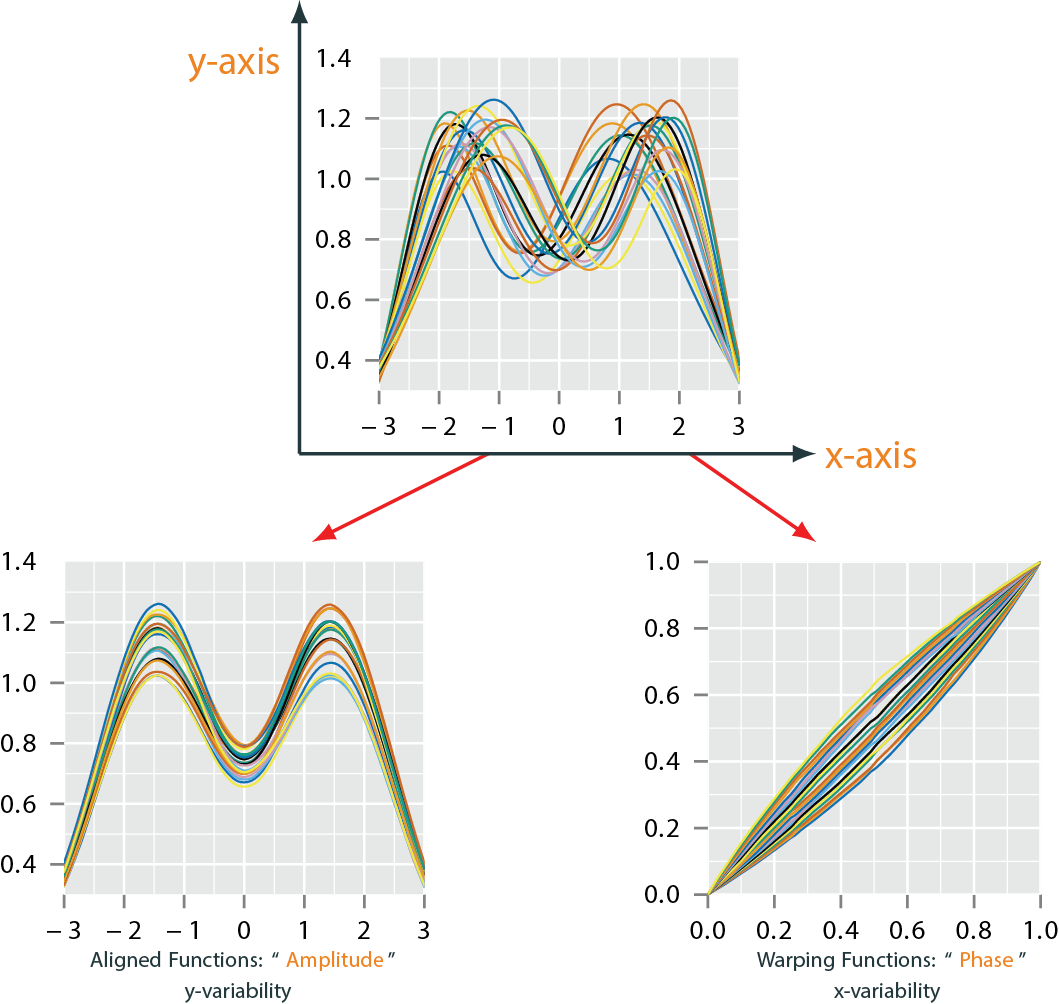
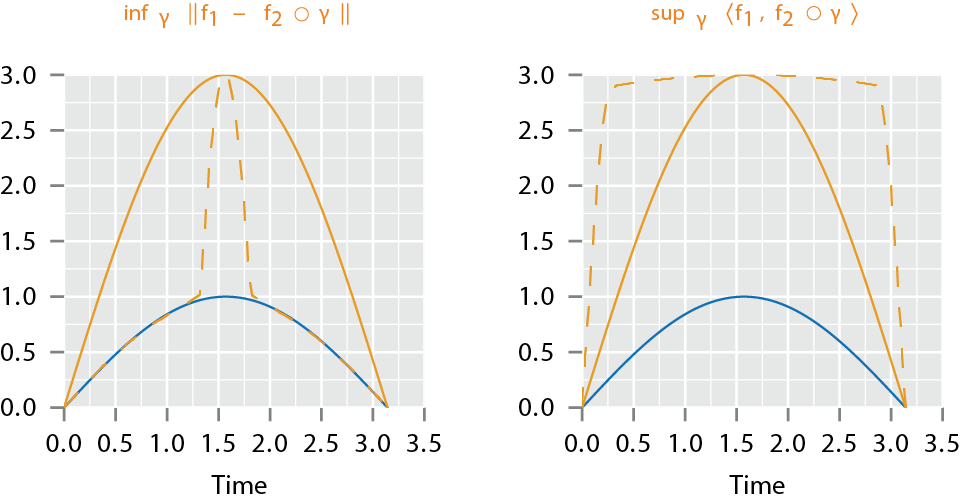
Pinching Problem
- Why use the ?
- The \({\mathbb{L}^2}\) distance is a proper distance
- The action of \(\Gamma\) does act by isometries
- Solves the pinching problem
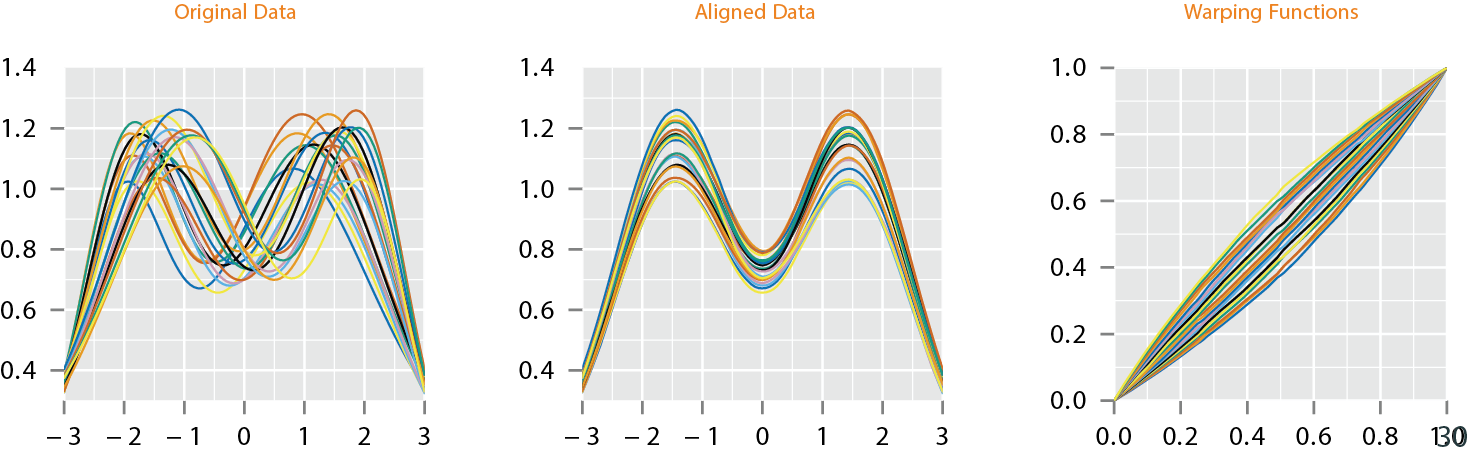
Elastic Function Alignment
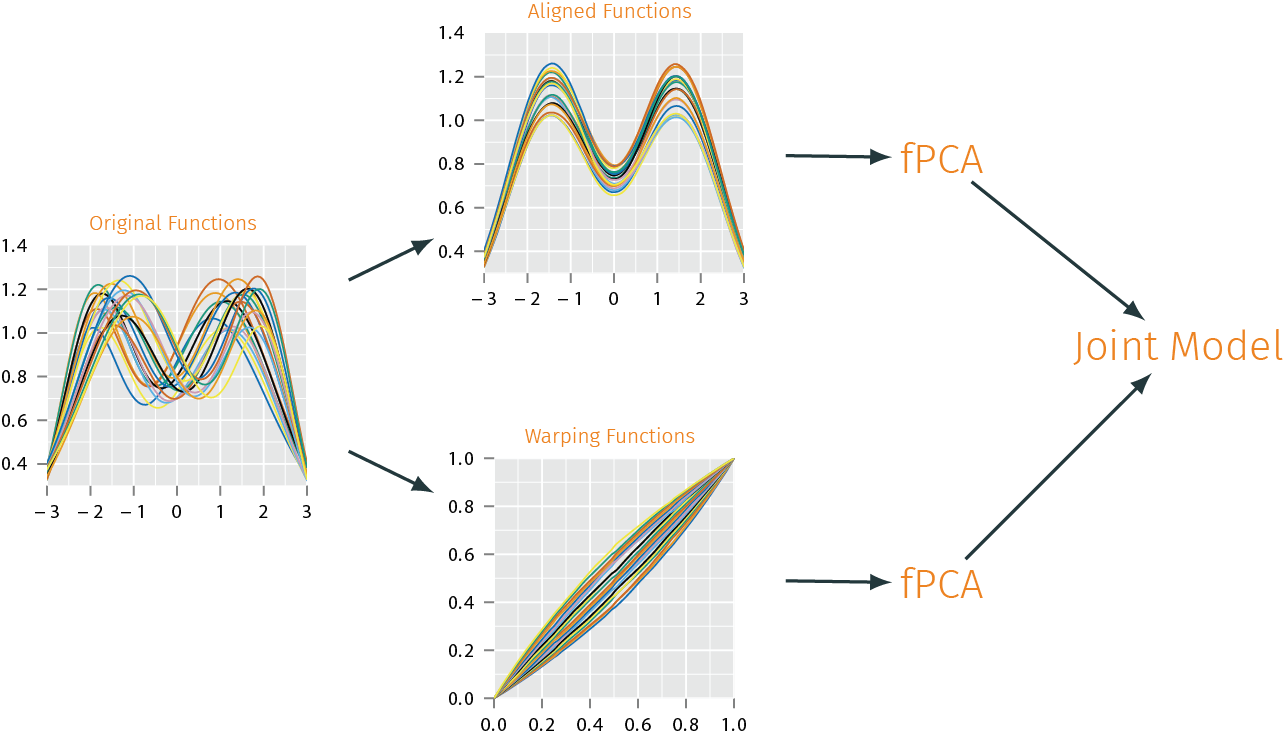
Modeling using Phase & Amplitude Separation
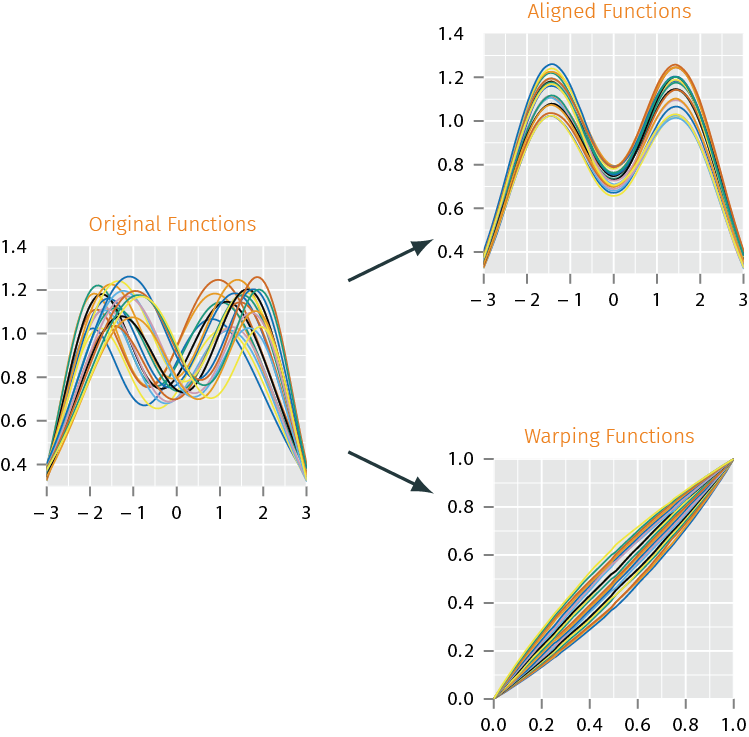
Modeling using Phase & Amplitude Separation
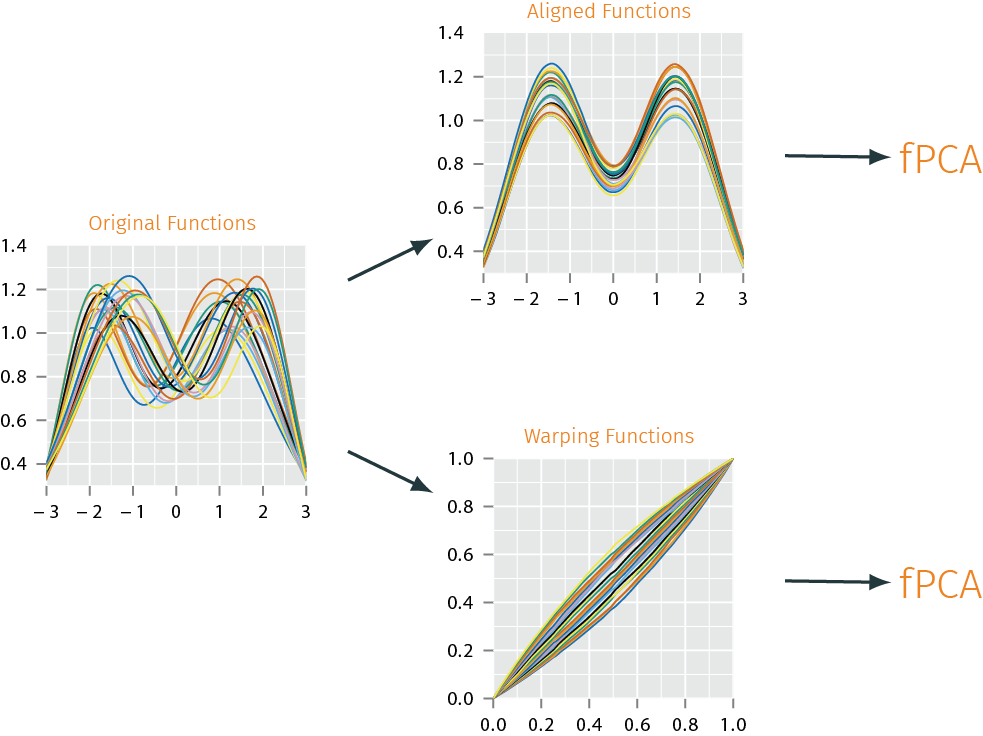
Modeling using Phase & Amplitude Separation
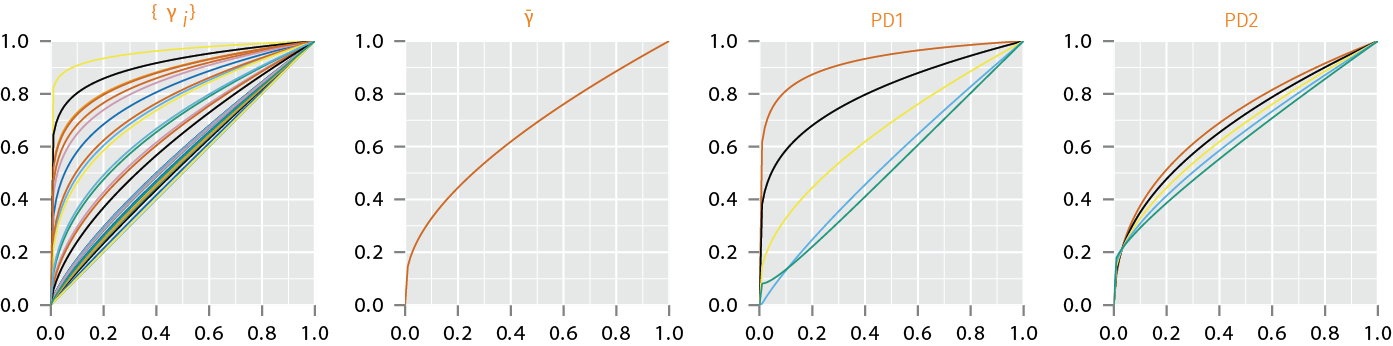
Analysis of Warping Functions (Phase)
- Horizontal fPCA: Analysis of Warping Functions
- Use SRSF of warping functions, \(\psi = \sqrt{\dot{\gamma}}\)
- Karcher Mean: \(\gamma \mapsto \sum_{i=1}^n d_p(\gamma, \gamma_i)^2\)
- Tangent Space:\(T_{\psi}({\mathbb{S}}_{\infty}) = \{v \in {\mathbb{L}^2}| \int_0^1 v(t) \psi(t) dt = 0\}\)
- Sample Covariance Function: \((t_1, t_2) \mapsto \frac{1}{n-1} \sum_{i=1}^n v_i(t_1) v_i(t_2)\)
- Take SVD of \(K_{\psi} = U_{\psi} \Sigma_{\psi} V_{\psi}^{\mathsf{T}}\) provides the estimated principal components
Why SRSF of \(\gamma_i\)
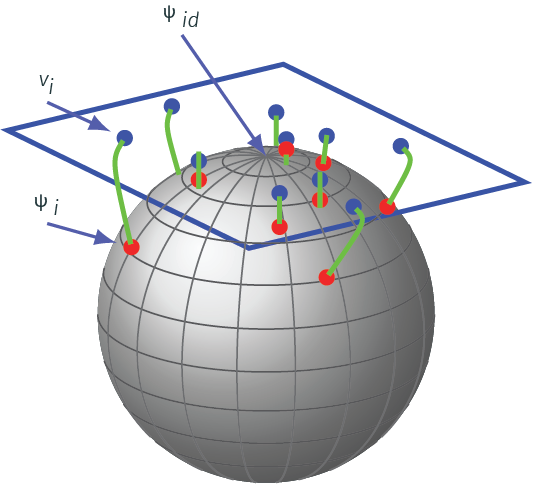
- \(\Gamma\) is a nonlinear manifold and it is infinite dimensional
- Represent an element \(\gamma \in \Gamma\) by the square-root of its derivative \(\psi = \sqrt{\dot{\gamma}}\)
- Important advantage of this transformation is that set of all such \(\psi\)s is a Hilbert sphere \({\mathbb{S}}_{\infty}\)
Analysis of Aligned Functions (Amplitude)
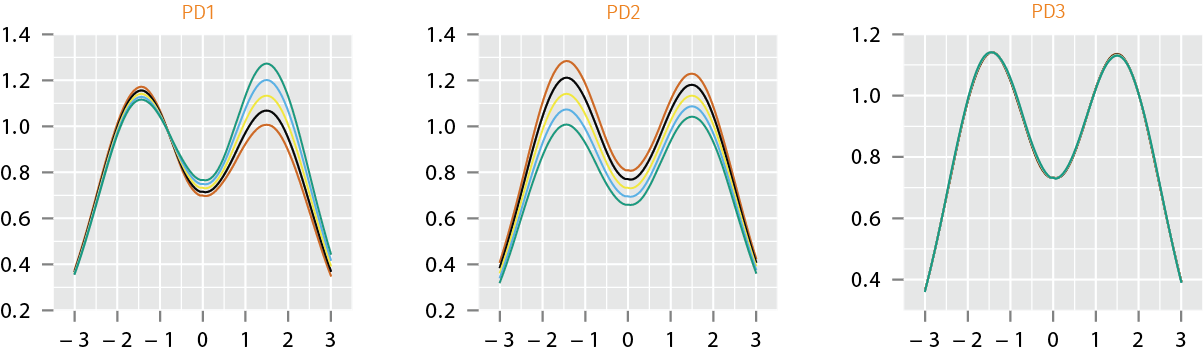
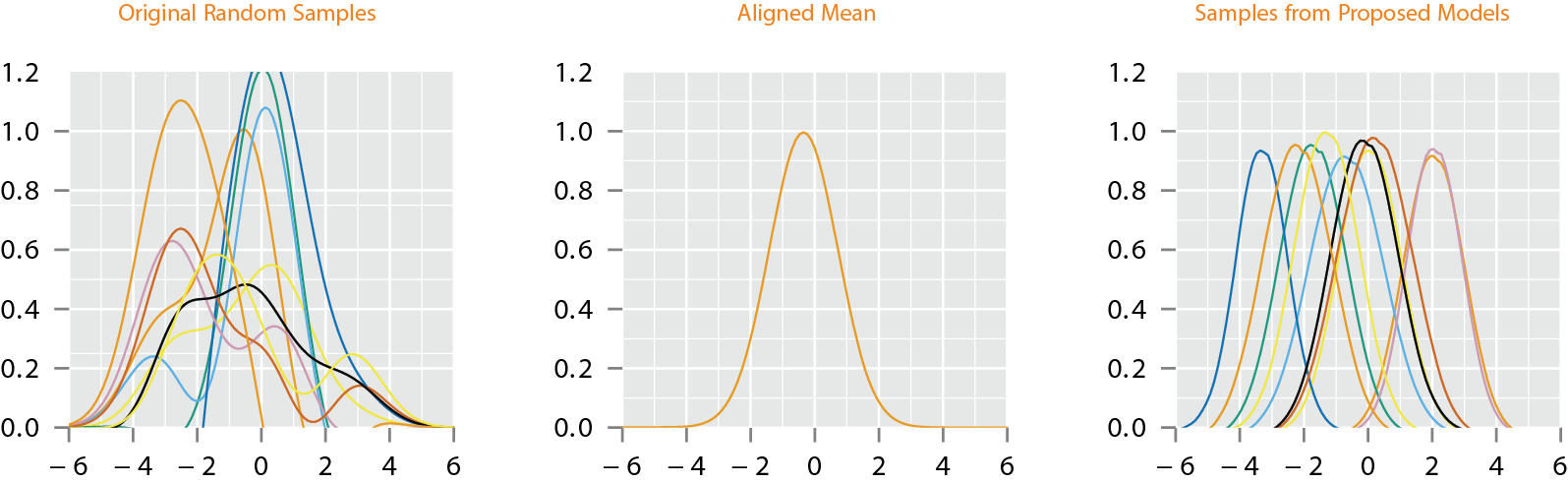
Sampling from Joint Model
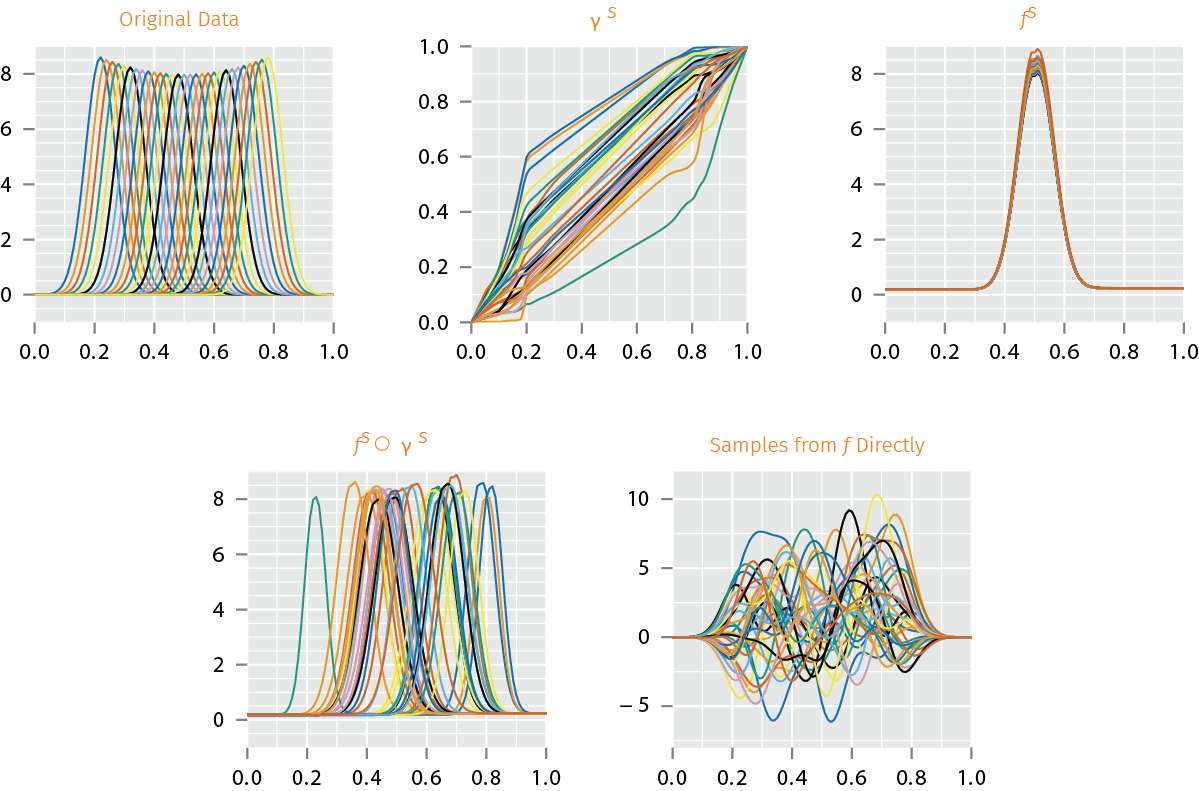
- Random samples from jointly Gaussian models on fPCA coefficients of \(\gamma^s\) and \(f^s\), and their combinations \(f^s \circ \gamma^s\), with samples from \(f\) directly.
Questions?
jdtuck@sandia.gov
http://research.tetonedge.net
